Anaconda 配置
YOLO 环境配置
下载YOLO代码,你也可以去yolo的github仓库下载(YOLO V5 版本5.0)(路径不要有中文):
https://gitee.com/song-laogou/yolov5-mask-42在该目录下开启终端:
在此路径下创建虚拟环境:
conda create -n yolo5 python==3.8.5
上述命令安装的环境如果在C盘,若你想安装在其他的磁盘,执行如下命令
conda create -p F:\anaconda3\envs\yolo_v5 python=3.8.5conda: 这是Conda软件包管理系统的命令行工具。create: 这个命令告诉Conda要创建一个新的环境。-n yolo5:-n参数用于指定创建的环境的名称,这里是 "yolo5"。你可以根据自己的需要选择一个合适的名称。python==3.8.5: 这个参数告诉Conda在新的环境中安装Python的特定版本,即3.8.5。双等号"=="表示精确匹配版本号,确保安装的是Python 3.8.5版本。
创建成功后激活虚拟环境:
conda activate yolo5查看目前有多少个虚拟环境:
conda info --envs删除虚拟环境:
conda env remove --name yolo5更多conda命令请自行了解
安装pytorch:
进入pytorch官网
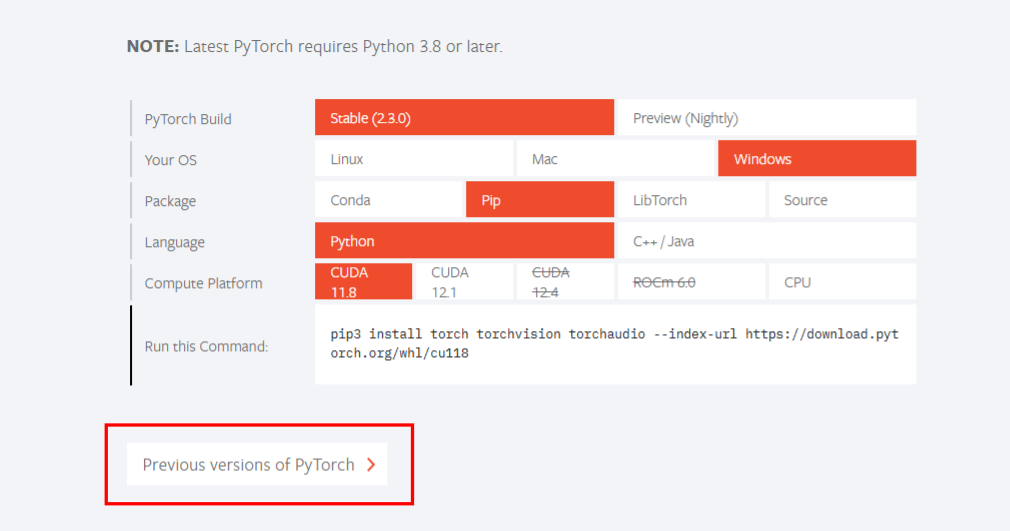
找到windows版本以及适合自己电脑的cuda版本:
举个例子:
Linux and Windows
# ROCM 5.7 (Linux only)
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/rocm5.7
# CUDA 11.8
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# CPU only
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cpu选择合适的cuda版本安装即可,建议pytorch 1.8版本即可

例如我的cuda版本 12.3.99,可以选择低于或等于自己cuda版本的pytorch安装即可,例如:
# CUDA 12.1
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121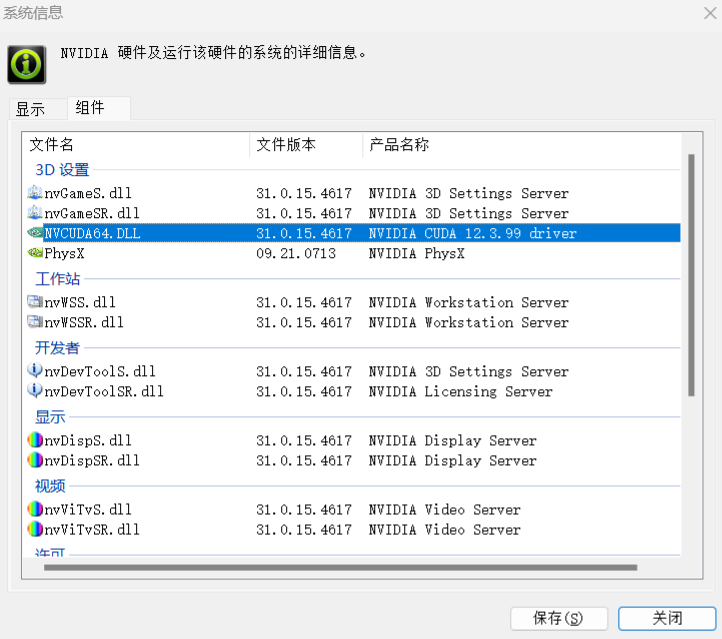
推荐安装1.8版本,版本号最好不要超过2
powershell如果无法执行,请执行
在powershell中执行 set-ExecutionPolicy RemoteSigned安装其他的依赖包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,在yolov5-mask-42-master目录下直接执行下列指令即可完成包的安装
pip install -r requirements.txt
pip install pyqt5
pip install labelme安装pycocotools
pip install pycocotools-windows测试
在yolov5目录下执行下列代码
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt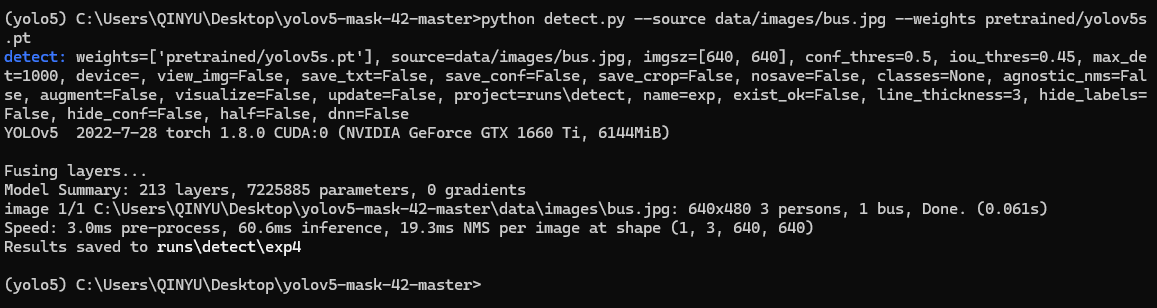
weights=['pretrained/yolov5s.pt']:使用了预训练的YOLOv5s模型权重文件。source=data/images/bus.jpg:输入的图像路径为data/images/bus.jpg。imgsz=[640, 640]:将输入图像调整为大小为640×640像素。conf_thres=0.5:置信度阈值,低于该阈值的检测结果将被过滤掉。iou_thres=0.45:IoU(交并比)阈值,用于非极大值抑制。max_det=1000:最大检测框数目。device=:未指定设备,将使用默认设备进行推理(可能是GPU)。view_img=False:不显示推理过程中的图像窗口。save_txt=False:不保存检测结果的文本文件。save_conf=False:不保存检测结果的置信度图像。save_crop=False:不保存检测结果的裁剪图像。nosave=False:保存检测结果。classes=None:未指定特定的类别,将检测所有可能的类别。agnostic_nms=False:使用类别感知的非极大值抑制。augment=False:不使用数据增强。visualize=False:不可视化推理结果。update=False:不更新YOLOv5模型。project=runs\detect:保存结果的目录为runs\detect。name=exp:实验名称为exp。exist_ok=False:如果结果目录已存在,则不覆盖。line_thickness=3:绘制边界框的线条粗细为3。hide_labels=False:显示类别标签。hide_conf=False:显示置信度分数。half=False:不使用混合精度推理。dnn=False:不使用DNN模块。
接下来的输出指示了模型的版本、使用的设备、图像处理速度以及检测结果。在这个例子中,模型成功地检测到了1辆公交车和3个人,并在运行目录的runs\detect\exp4保存了结果
在Pycharm中配置anaconda虚拟环境
数据处理
在激活的虚拟环境下执行
pip install labelimg -i https://mirror.baidu.com/pypi/simple
labelimg软件启动后的界面如下:
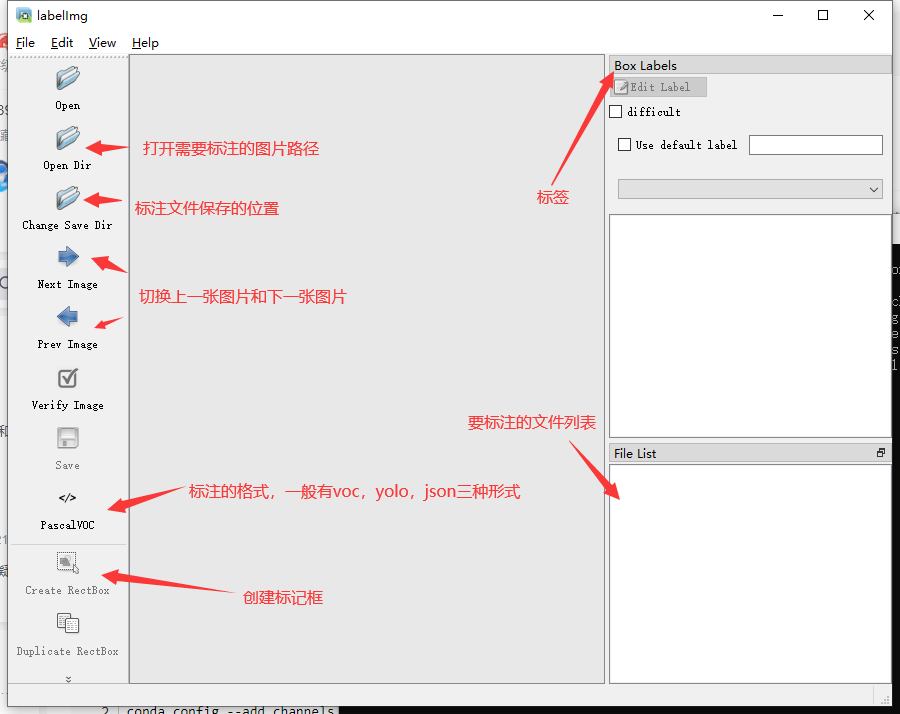
标注过程如下:
1.打开图片目录
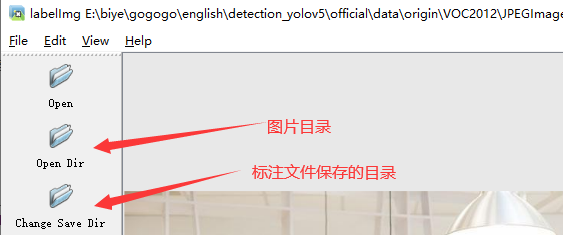
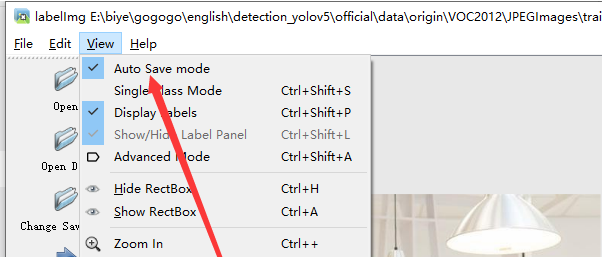
2.设置标注文件保存的目录并设置自动保存
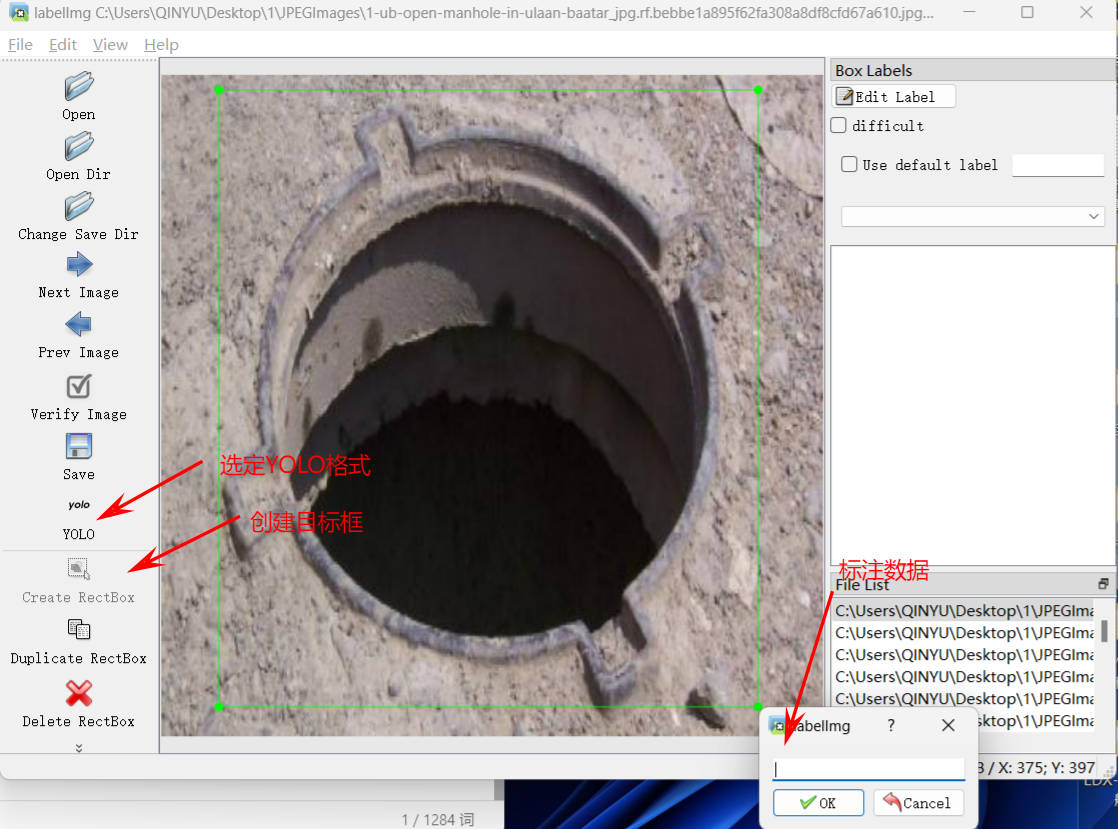
3.开始标注,画框,标记目标的label,crtl+s保存,然后d切换到下一张继续标注,不断重复重复
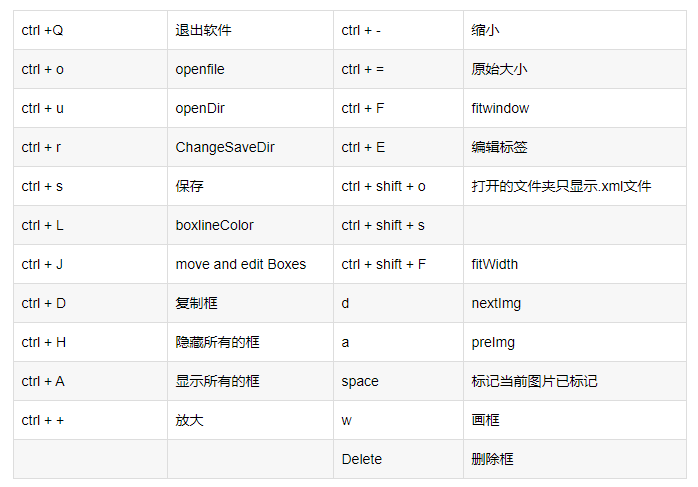
labelimg的快捷键如下,学会快捷键可以帮助你提高数据标注的效率:
标准完成之后得到一系列txt文件,txt文件为目标检查文件,该文件名与图片的文件名一一对应,如下图:
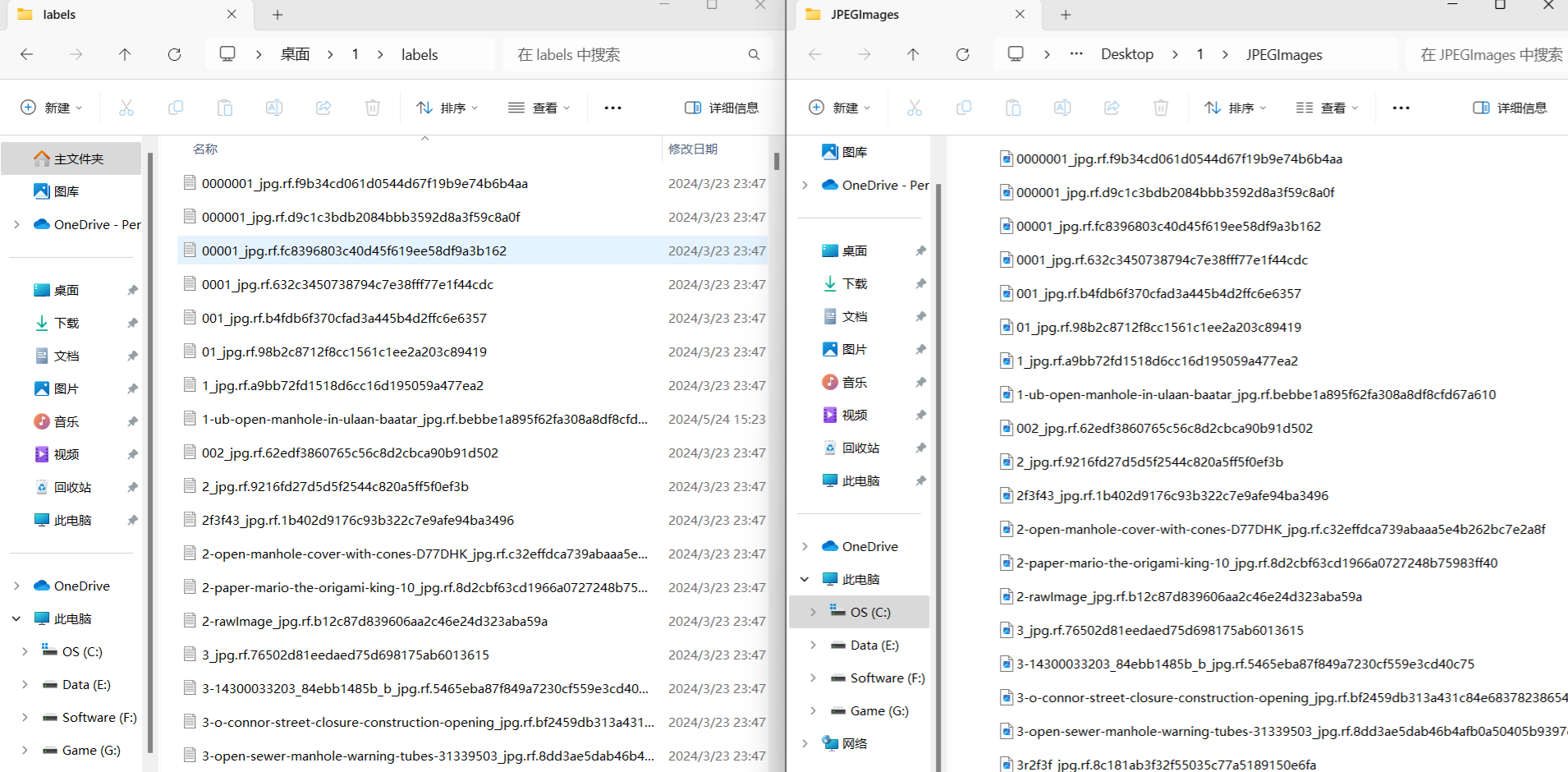
打开具体的标注文件,你将会看到下面的内容,txt文件中每一行表示一个目标,以空格进行区分,分别表示目标的类别id,归一化处理之后的中心点x坐标、y坐标、目标框的w和h。

4.修改数据集配置文件
标记完成的数据请按照下面的格式进行放置,方便程序进行索引。
YOLO_Mask
└─ score
├─ images
│ ├─ test # 下面放测试集图片
│ ├─ train # 下面放训练集图片
│ └─ val # 下面放验证集图片
└─ labels
├─ test # 下面放测试集标签
├─ train # 下面放训练集标签
├─ val # 下面放验证集标签
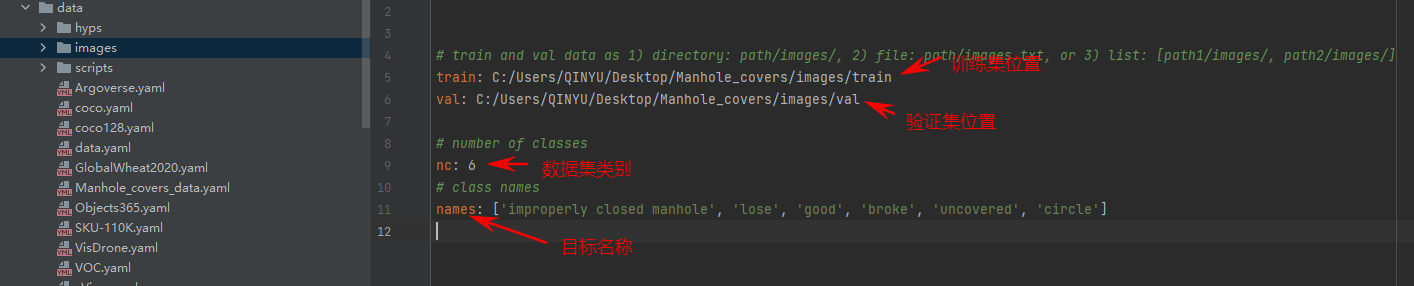
这里的配置文件是为了方便我们后期训练使用,我们需要在data目录下创建一个Manhole_covers_data.yaml的文件,如下图所示:
模型训练
模型的基本训练
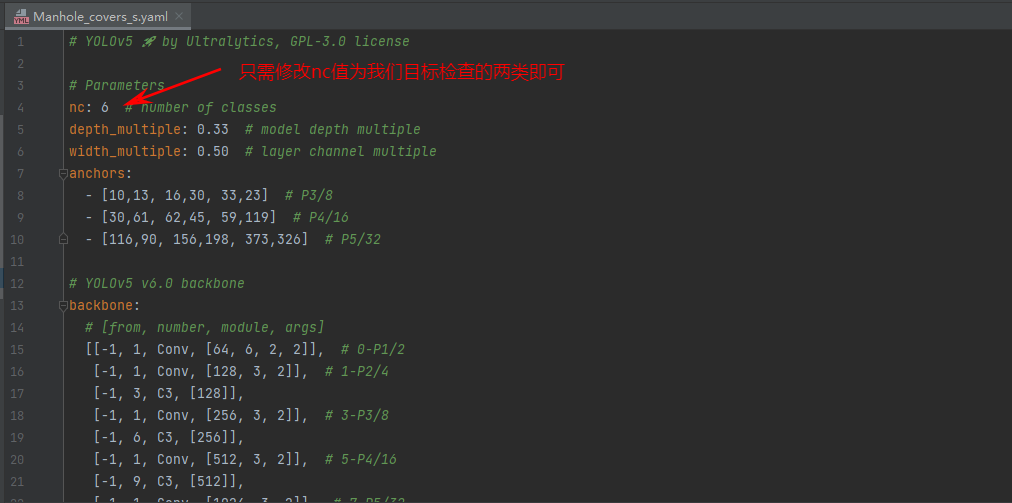
在models下建立一个Manhole_covers_s.yaml的模型配置文件,内容如下:
执行下列代码运行程序即可:
python train.py --data Manhole_covers_data.yaml --cfg Manhole_covers_s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
在train/runs/exp的目录下可以找到训练得到的模型和日志文件
若没有执行完整的训练过程,执行如下指令可验证此时的权重文件:
python val.py --data data/Manhole_covers_data.yaml --weights runs/train/exp8/weights/best.pt --img 640